
Kritik Terhadap Teori Reinforcement Learning


Smallest Font
Largest Font
Table of Contents
- Kelemahan Teori Reinforcement Learning
-
- Tiga Kelemahan Utama Reinforcement Learning
- Perbandingan Reinforcement Learning dengan Pendekatan Pembelajaran Lain
- Tabel Perbandingan Metode Pembelajaran
- Pengaruh Masalah Eksplorasi-Eksploitasi pada Kinerja Algoritma RL
- Contoh Skenario Kegagalan RL karena Keterbatasan Teoritis
- Pengaruh Bias dalam Reward Function
- Perbandingan DQN dan A2C dalam Menangani Non-stationarity dan Partial Observability
- Batasan dan Asumsi Teori Reinforcement Learning
- Masalah Skalabilitas dan Kompleksitas Komputasi: Kritik Terhadap Teori Reinforcement
-
- Tantangan Komputasi pada Masalah Berskala Besar
- Kompleksitas Komputasi Membatasi Penerapan RL pada Sistem Kompleks
- Teknik Mengatasi Masalah Skalabilitas dalam RL
- Perbandingan Kompleksitas Komputasi RL dengan Metode Pembelajaran Mesin Lainnya
- Solusi Mengatasi Kompleksitas Komputasi dalam Implementasi Algoritma RL
- Keterbatasan Data dan Pembelajaran yang Tidak Efisien
- Interpretasi dan Pemahaman Model Reinforcement Learning
- Pertimbangan Etis dalam Reinforcement Learning
-
- Potensi Bias dalam Algoritma Reinforcement Learning
- Panduan Etika Pengembangan dan Penerapan Reinforcement Learning
- Implikasi Etis Reinforcement Learning dalam Sistem Peradilan Pidana
- Fairness dan Accountability dalam Sistem Penentuan Kelayakan Kredit
- Dampak Negatif Reinforcement Learning dalam Sistem Otonom
- Perbandingan Reinforcement Learning dengan Pendekatan Pembelajaran Lain
- Studi Kasus Kegagalan Reinforcement Learning
- Pengembangan dan Perbaikan Algoritma Reinforcement Learning
- Aplikasi Reinforcement Learning yang Bermasalah
-
- Contoh Aplikasi RL yang Bermasalah: Sistem Rekomendasi yang Menimbulkan Kecanduan
- Potensi Dampak Negatif Sistem Rekomendasi yang Berbasis RL
- Mengatasi dan Meminimalisir Masalah Sistem Rekomendasi
- Rekomendasi untuk Pengembangan Aplikasi RL yang Lebih Bertanggung Jawab
- Saran untuk Regulasi dan Pedoman Etika dalam Penggunaan RL, Kritik terhadap teori reinforcement
- Pengaruh Reward Function terhadap Hasil Pembelajaran
- Generalisasi dan Transfer Learning dalam Reinforcement Learning
-
- Tantangan Generalisasi dalam Reinforcement Learning
- Teknik Transfer Learning untuk Meningkatkan Generalisasi
- Penerapan Transfer Learning dalam Permainan Atari: Breakout ke Pong
- Keuntungan dan Kerugian Transfer Learning dalam Reinforcement Learning
- Pentingnya Generalisasi dalam Reinforcement Learning
- Perbandingan Tiga Teknik Transfer Learning
- Pengaruh Pemilihan Fitur terhadap Keberhasilan Transfer Learning
- Kemampuan Eksplorasi dan Eksploitasi
- Implementasi Praktis Algoritma Reinforcement Learning
- Analisis Sensitivitas Parameter dalam Reinforcement Learning
-
- Pengaruh Perubahan Parameter terhadap Hasil Q-learning di Grid World
- Analisis Sensitivitas Parameter dengan 10 Iterasi
- Teknik Hyperparameter Tuning: Grid Search dan Random Search
- Perbandingan Hasil Learning Rate 0.1, 0.01, dan 0.5
- Pentingnya Penentuan Parameter yang Tepat
- Keterbatasan Analisis Sensitivitas
- Ulasan Penutup
Kritik terhadap teori reinforcement learning: Bosan dengan AI yang selalu sempurna? Ternyata, di balik kecanggihannya, teori reinforcement learning menyimpan sejumlah kelemahan yang bikin geleng-geleng kepala. Dari masalah data hingga bias algoritma, petualangan AI ini ternyata jauh lebih rumit dari yang dibayangkan. Siap-siap menyelami sisi gelap kecerdasan buatan!
Reinforcement learning, metode pembelajaran mesin yang memungkinkan mesin belajar melalui trial and error, memang menawarkan potensi luar biasa. Namun, perjalanan menuju kecerdasan buatan yang sempurna ternyata dipenuhi dengan rintangan. Artikel ini akan mengupas tuntas berbagai kritik terhadap teori reinforcement learning, mulai dari kelemahan algoritma hingga implikasi etisnya. Kita akan melihat bagaimana reward sparsity, curse of dimensionality, dan sample inefficiency menjadi momok menakutkan dalam pengembangannya. Selain itu, kita juga akan membahas batasan data, kompleksitas komputasi, serta tantangan interpretasi model yang kompleks. Siap untuk mengungkap misteri di balik layar kecerdasan buatan?
Kelemahan Teori Reinforcement Learning
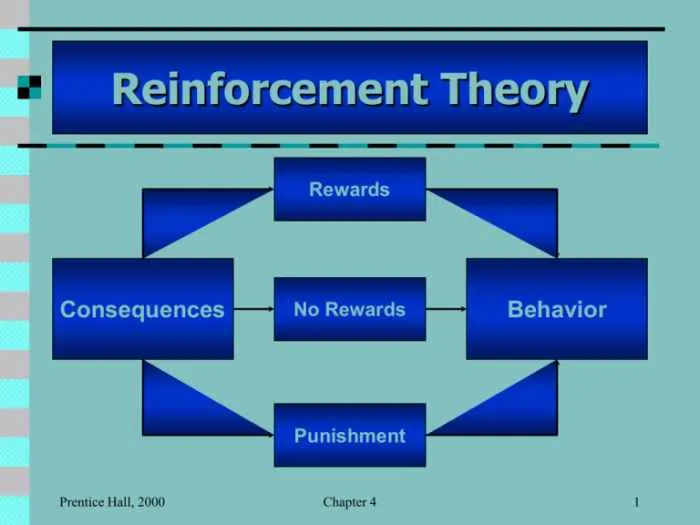
Reinforcement Learning (RL), meskipun menawarkan potensi luar biasa dalam berbagai aplikasi, bukanlah solusi ajaib untuk semua permasalahan pembelajaran mesin. Di balik pesona kemampuannya dalam membuat agen cerdas, terdapat beberapa kelemahan signifikan yang perlu dipahami. Artikel ini akan mengupas tuntas kelemahan-kelemahan tersebut, mulai dari masalah *reward sparsity* hingga bias dalam *reward function*, dengan contoh-contoh kasus nyata yang akan membuatmu melek akan kompleksitas RL.

Tiga Kelemahan Utama Reinforcement Learning
Tiga kelemahan utama RL yang sering menjadi batu sandungan adalah *reward sparsity*, *curse of dimensionality*, dan *sample inefficiency*. Ketiga hal ini saling berkaitan dan seringkali muncul secara bersamaan, membuat proses pelatihan RL menjadi rumit dan membutuhkan sumber daya yang besar.
- Reward Sparsity: Dalam RL, agen hanya menerima *reward* pada momen-momen tertentu, bukan di setiap langkah. Ini menyulitkan agen untuk mempelajari strategi optimal karena informasi yang diterima sangat sedikit. Bayangkan robot yang belajar berjalan: ia hanya mendapat *reward* ketika berhasil mencapai tujuan, bukan saat mengambil langkah-langkah kecil di tengah perjalanan. Hal ini membuat proses pembelajaran menjadi sangat lambat dan tidak efisien.
- Curse of Dimensionality: Semakin kompleks lingkungan atau *state space* yang dihadapi agen, semakin besar pula jumlah kemungkinan keadaan yang harus dipelajari. Ini menyebabkan eksponensial peningkatan kebutuhan memori dan waktu komputasi. Sebagai contoh, sebuah game catur memiliki *state space* yang sangat besar, membuat pelatihan RL menjadi sangat menantang dan membutuhkan waktu yang sangat lama, bahkan dengan komputer super sekalipun.
- Sample Inefficiency: RL membutuhkan banyak data untuk mempelajari strategi optimal. Agen harus mencoba berbagai tindakan dan mengamati hasilnya untuk mendapatkan pemahaman yang cukup tentang lingkungan. Hal ini membutuhkan waktu dan sumber daya yang signifikan, terutama dalam lingkungan yang kompleks dan berbahaya. Misalnya, melatih mobil self-driving dengan RL membutuhkan ribuan jam simulasi atau uji coba di dunia nyata untuk mencapai kinerja yang aman dan handal.
Perbandingan Reinforcement Learning dengan Pendekatan Pembelajaran Lain
Dibandingkan dengan *supervised learning* dan *unsupervised learning*, RL memiliki karakteristik yang berbeda, terutama dalam hal kebutuhan data, waktu pelatihan, dan interpretasi model. Perbedaan ini perlu dipertimbangkan saat memilih metode pembelajaran yang tepat untuk suatu permasalahan.
- Kebutuhan Data: RL umumnya membutuhkan data yang jauh lebih banyak dibandingkan *supervised learning*. *Supervised learning* dapat belajar dari data yang sudah diberi label, sementara RL harus belajar melalui interaksi dengan lingkungan dan *trial-and-error*.
- Waktu Pelatihan: Proses pelatihan RL seringkali memakan waktu yang jauh lebih lama dibandingkan *supervised learning* dan *unsupervised learning*. Hal ini disebabkan oleh kebutuhan untuk mengeksplorasi berbagai kemungkinan tindakan dan mengamati hasilnya.
- Kompleksitas Implementasi: RL umumnya lebih kompleks untuk diimplementasikan dibandingkan *supervised learning* dan *unsupervised learning*. Hal ini disebabkan oleh kebutuhan untuk merancang *reward function*, *state space*, dan algoritma pembelajaran yang tepat.
Tabel Perbandingan Metode Pembelajaran
Tabel berikut ini memberikan perbandingan singkat antara beberapa algoritma RL, *supervised learning*, dan *unsupervised learning*, meliputi kekuatan dan kelemahan masing-masing serta contoh penerapannya.

| Metode Pembelajaran | Jenis Pembelajaran | Kekuatan | Kelemahan | Contoh Penerapan |
|---|---|---|---|---|
| Q-learning | Reinforcement Learning | Relatif sederhana, mudah diimplementasikan | Perlu banyak data, rentan terhadap *reward sparsity* | Game sederhana, robot navigasi |
| SARSA | Reinforcement Learning | Lebih stabil dibandingkan Q-learning | Perlu banyak data, rentan terhadap *reward sparsity* | Robot kontrol, game sederhana |
| Deep Q-Network (DQN) | Reinforcement Learning | Dapat menangani *state space* yang besar | Membutuhkan banyak data dan daya komputasi, rentan terhadap *overfitting* | Game Atari, robot manipulasi |
| Regresi Linear | Supervised Learning | Sederhana, mudah diinterpretasikan | Asumsi linearitas, rentan terhadap *outliers* | Prediksi harga rumah, analisis sentimen |
| Regresi Logistik | Supervised Learning | Dapat digunakan untuk klasifikasi biner | Asumsi linearitas, rentan terhadap *outliers* | Deteksi spam, prediksi churn pelanggan |
| K-Means Clustering | Unsupervised Learning | Sederhana, mudah diimplementasikan | Membutuhkan menentukan jumlah cluster, sensitif terhadap *outliers* | Segmentasi pelanggan, pengelompokan dokumen |
| Principal Component Analysis (PCA) | Unsupervised Learning | Reduksi dimensi, visualisasi data | Asumsi data linear, informasi dapat hilang | Analisis citra, pengolahan sinyal |
Pengaruh Masalah Eksplorasi-Eksploitasi pada Kinerja Algoritma RL
Dalam RL, agen harus menyeimbangkan antara eksplorasi (mencoba tindakan baru) dan eksploitasi (melakukan tindakan yang sudah diketahui memberikan *reward* terbaik). Ketidakseimbangan ini dapat secara signifikan mempengaruhi kinerja algoritma.
- ε-greedy: Strategi ini memilih tindakan acak dengan probabilitas ε dan tindakan terbaik dengan probabilitas 1-ε. Sederhana, tetapi dapat kurang efisien dalam lingkungan dengan *reward sparsity* yang tinggi.
- Softmax: Strategi ini memilih tindakan berdasarkan probabilitas yang dihitung dari nilai *Q* dari setiap tindakan. Lebih halus daripada ε-greedy, tetapi masih bisa terjebak dalam *local optima*.
- Upper Confidence Bound (UCB): Strategi ini memilih tindakan berdasarkan perkiraan nilai *Q* dan ketidakpastiannya. Lebih eksploratif daripada ε-greedy dan softmax, tetapi lebih kompleks untuk diimplementasikan.
Contoh Skenario Kegagalan RL karena Keterbatasan Teoritis
Berikut skenario di mana RL gagal mencapai hasil optimal karena *reward function* yang buruk. Bayangkan robot yang dirancang untuk membersihkan ruangan. Jika *reward function* hanya memberikan *reward* berdasarkan jumlah debu yang dibersihkan, robot mungkin akan fokus membersihkan area kecil dengan banyak debu daripada membersihkan seluruh ruangan secara efisien. Ini karena *reward function* tidak menangkap tujuan keseluruhan dari tugas tersebut.
Diagram alur sederhana:

- Robot memulai pembersihan.
- Robot mendeteksi area dengan banyak debu.
- Robot membersihkan area tersebut dan mendapatkan *reward* tinggi.
- Robot mengabaikan area lain yang kurang kotor, meskipun area tersebut penting untuk dibersihkan secara keseluruhan.
- Robot menyelesaikan pembersihan dengan *reward* total yang tinggi, tetapi ruangan tidak bersih secara keseluruhan.
Hal ini dapat diatasi dengan merancang *reward function* yang lebih komprehensif, misalnya dengan memberikan *reward* berdasarkan persentase area yang dibersihkan dan tingkat kebersihannya.
Pengaruh Bias dalam Reward Function
Bias dalam *reward function* dapat menyebabkan agen belajar perilaku yang tidak diinginkan. Misalnya, jika *reward function* untuk mobil self-driving memberikan *reward* yang lebih tinggi untuk kecepatan daripada keselamatan, mobil tersebut mungkin akan mengemudi dengan kecepatan tinggi, meskipun berisiko kecelakaan. Ini menunjukkan betapa pentingnya merancang *reward function* yang mencerminkan tujuan sebenarnya dan mempertimbangkan semua aspek penting.
Perbandingan DQN dan A2C dalam Menangani Non-stationarity dan Partial Observability
DQN dan A2C merupakan dua algoritma RL yang populer, namun memiliki kelemahan dalam menangani *non-stationarity* dan *partial observability*.

- DQN: DQN relatif kurang efektif dalam menangani *non-stationarity* karena ia mempelajari nilai Q secara terpisah dari pengalaman yang telah dikumpulkan sebelumnya. Perubahan lingkungan dapat membuat pengetahuan yang telah dipelajari menjadi tidak relevan.
- A2C: A2C memiliki kinerja yang lebih baik dalam menangani *non-stationarity* karena ia memperbarui nilai Q secara terus menerus. Namun, A2C masih bisa kesulitan dalam situasi *partial observability* karena ia hanya memiliki informasi yang terbatas tentang lingkungan.
Non-stationarity mengacu pada perubahan lingkungan atau dinamika sistem selama proses pembelajaran, sedangkan partial observability mengacu pada situasi di mana agen tidak memiliki akses penuh terhadap informasi keadaan lingkungan.
Batasan dan Asumsi Teori Reinforcement Learning

Reinforcement Learning (RL), meski menawarkan potensi luar biasa dalam berbagai aplikasi, bukanlah solusi ajaib. Suksesnya RL sangat bergantung pada beberapa asumsi kunci yang seringkali tidak terpenuhi di dunia nyata. Memahami batasan-batasan ini krusial untuk menghindari kekecewaan dan merancang sistem RL yang lebih robust dan efektif. Mari kita bongkar beberapa asumsi kunci RL dan implikasinya.
Asumsi Kunci dalam Reinforcement Learning
Tiga asumsi kunci yang mendasari teori reinforcement learning seringkali menjadi batu sandungan dalam penerapannya. Berikut tabel yang merangkumnya:

| Asumsi | Penjelasan | Implikasi Pelanggaran |
|---|---|---|
| Lingkungan yang sepenuhnya dapat diamati | Agent memiliki akses penuh terhadap informasi state lingkungan saat ini. | Agent mungkin membuat keputusan yang suboptimal karena informasi yang tidak lengkap. |
| Reward yang konsisten dan tepat | Reward yang diberikan konsisten merepresentasikan tujuan pembelajaran. | Agent mungkin belajar perilaku yang tidak diinginkan atau gagal mencapai tujuan. |
| Model lingkungan yang diketahui (atau dapat dipelajari) | Agent memiliki pemahaman tentang bagaimana tindakannya mempengaruhi state lingkungan. | Agent membutuhkan waktu lebih lama untuk belajar atau bahkan gagal belajar sama sekali. |
Implikasi Pelanggaran Asumsi
Pelanggaran terhadap asumsi-asumsi di atas memiliki konsekuensi signifikan terhadap kinerja algoritma RL. Mari kita bahas lebih detail.
Lingkungan yang sepenuhnya dapat diamati: Jika agent tidak memiliki akses penuh terhadap informasi state (misalnya, sebagian informasi tersembunyi), agent mungkin membuat keputusan yang suboptimal. Bayangkan robot yang membersihkan rumah, tetapi hanya bisa melihat sebagian ruangan. Robot tersebut mungkin akan membersihkan area yang terlihat bersih berkali-kali, mengabaikan area yang kotor tetapi tersembunyi. Akurasi dan efisiensi pembersihan akan menurun drastis.
Reward yang konsisten dan tepat: Reward yang tidak konsisten atau tidak tepat dapat menyebabkan agent belajar perilaku yang tidak diinginkan. Misalnya, jika agent RL dilatih untuk bermain game dan reward diberikan secara acak, agent tersebut tidak akan dapat belajar strategi yang efektif. Akurasi dan stabilitas pembelajaran akan terganggu. Agent mungkin terjebak dalam siklus reward yang tidak optimal.

Model lingkungan yang diketahui (atau dapat dipelajari): Jika model lingkungan tidak diketahui, agent harus menghabiskan lebih banyak waktu untuk mengeksplorasi lingkungan dan mempelajari dinamikanya. Hal ini mengurangi efisiensi pembelajaran. Contohnya, robot yang belajar berjalan tanpa model yang akurat tentang bagaimana kaki dan tubuhnya berinteraksi akan jatuh berkali-kali sebelum akhirnya mampu berjalan dengan stabil. Stabilitas dan efisiensi pembelajaran akan terpengaruh.
Pengaruh Lingkungan yang Teramati Sepenuhnya
Asumsi lingkungan yang sepenuhnya dapat diamati sangat penting dalam RL. Berikut beberapa poin yang menjelaskan pengaruhnya:
- Algoritma RL berbasis model, seperti Dynamic Programming dan Monte Carlo, sangat bergantung pada asumsi ini. Tanpa informasi lengkap, perencanaan optimal menjadi tidak mungkin.
- Jika asumsi ini dilanggar, algoritma mungkin mengalami kesulitan dalam menggeneralisasi pengetahuan ke situasi baru karena informasi yang tidak lengkap.
- Untuk mengatasi masalah ini, teknik seperti Partially Observable Markov Decision Processes (POMDPs) digunakan, yang mempertimbangkan ketidakpastian dalam observasi.
- Metode seperti Recurrent Neural Networks (RNNs) dapat digunakan untuk mengingat informasi dari observasi sebelumnya, membantu mengurangi dampak observasi yang tidak lengkap.
- Teknik lain termasuk menggunakan sensor yang lebih canggih atau meningkatkan frekuensi observasi.
Ketidakpastian dalam Lingkungan
Ketidakpastian dalam lingkungan merupakan tantangan besar bagi RL. Noise dalam observasi, transisi state yang stokastik, dan reward yang tidak pasti dapat menyebabkan kinerja yang buruk atau bahkan kegagalan.

Contoh Ketidakpastian: Bayangkan robot yang belajar menyetir mobil otonom. Ketidakpastian dalam lingkungan meliputi kondisi jalan yang berubah-ubah (hujan, es), perilaku tak terduga pengemudi lain, dan bahkan sensor yang bermasalah. Semua ini dapat menyebabkan kesalahan perencanaan dan keputusan yang berbahaya, sehingga membutuhkan sistem yang lebih robust untuk menangani ketidakpastian ini.
Contoh Dunia Nyata
Berikut beberapa contoh situasi di dunia nyata di mana asumsi RL tidak terpenuhi:
| Contoh | Asumsi yang Dilanggar | Pengaruh | Modifikasi Algoritma |
|---|---|---|---|
| Robot yang belajar berjalan di medan yang tidak rata | Lingkungan yang sepenuhnya dapat diamati, Model lingkungan yang diketahui | Ketidakstabilan, pembelajaran yang lambat | Menggunakan sensor yang lebih canggih, algoritma yang lebih robust terhadap noise, dan model lingkungan yang lebih akurat. |
| Sistem rekomendasi film yang mempertimbangkan preferensi pengguna yang dinamis | Reward yang konsisten dan tepat | Rekomendasi yang tidak akurat | Menggunakan algoritma yang dapat menangani perubahan preferensi pengguna, seperti model berbasis konteks. |
| Sistem perdagangan saham otomatis | Semua asumsi | Kehilangan uang, keputusan investasi yang buruk | Menggunakan algoritma yang lebih robust terhadap noise dan ketidakpastian, dan mempertimbangkan faktor-faktor eksternal seperti berita ekonomi. |
Masalah Skalabilitas dan Kompleksitas Komputasi: Kritik Terhadap Teori Reinforcement
Reinforcement learning (RL), meski keren dan menjanjikan, ternyata punya kendala yang bikin kepala pusing: skalabilitas dan kompleksitas komputasi. Bayangin aja, mau ngajarin robot main catur aja butuh waktu dan daya komputasi yang gak main-main. Nah, gimana kalau kita mau ngajarin robot ngelola lalu lintas kota Jakarta yang super padat? Itu baru sebagian kecil dari tantangan yang dihadapi RL dalam menghadapi masalah skala besar.
Kompleksitas komputasi dalam RL terutama berasal dari proses trial-and-error yang intensif. Algoritma RL perlu mencoba berbagai kombinasi aksi dan mempelajari konsekuensinya, yang bisa membutuhkan jutaan, bahkan miliaran iterasi, terutama pada lingkungan yang kompleks dan berdimensi tinggi. Semakin besar dan kompleks lingkungannya, semakin banyak waktu dan sumber daya komputasi yang dibutuhkan. Hal ini jelas membatasi penerapan RL pada sistem dunia nyata yang kompleks, seperti sistem kontrol industri, robotika canggih, atau bahkan game yang super realistis.
Tantangan Komputasi pada Masalah Berskala Besar
Penerapan RL pada masalah berskala besar menghadapi beberapa tantangan komputasi yang signifikan. Salah satunya adalah eksplosi ruang status-aksi. Pada masalah yang kompleks, jumlah kemungkinan status dan aksi bisa sangat besar, sehingga algoritma RL membutuhkan waktu yang sangat lama untuk menjelajahi seluruh ruang tersebut. Selain itu, waktu pelatihan yang lama dan kebutuhan memori yang besar juga menjadi kendala utama. Bayangkan melatih model RL untuk mengontrol lalu lintas di kota besar – jumlah data yang dibutuhkan, kompleksitas simulasi, dan waktu pelatihan akan sangat besar. Ini membutuhkan infrastruktur komputasi yang powerful dan mahal.
Kompleksitas Komputasi Membatasi Penerapan RL pada Sistem Kompleks
Kompleksitas komputasi yang tinggi seringkali membuat RL tidak praktis untuk diterapkan pada sistem yang kompleks dan dinamis. Misalnya, mengontrol robot humanoid yang harus berinteraksi dengan lingkungan yang tidak terstruktur dan berubah-ubah membutuhkan kemampuan komputasi yang jauh melampaui kemampuan komputer saat ini. Proses pembelajaran RL yang bergantung pada simulasi juga menjadi masalah, karena simulasi yang akurat dan detail untuk sistem kompleks bisa sangat kompleks dan membutuhkan waktu komputasi yang lama. Akibatnya, implementasi RL pada sistem tersebut seringkali tidak efisien dan mahal.
Teknik Mengatasi Masalah Skalabilitas dalam RL
- Penggunaan arsitektur jaringan saraf yang lebih efisien: Arsitektur seperti convolutional neural networks (CNNs) dan recurrent neural networks (RNNs) dapat mengurangi jumlah parameter dan meningkatkan efisiensi komputasi.
- Teknik sampling yang canggih: Teknik seperti Importance Sampling dan Monte Carlo Tree Search dapat mengurangi jumlah interaksi yang dibutuhkan dengan lingkungan simulasi.
- Transfer learning: Dengan memanfaatkan pengetahuan yang diperoleh dari tugas yang serupa, model RL dapat dilatih lebih cepat dan efisien.
- Parallelisasi dan distributed computing: Membagi tugas komputasi ke beberapa mesin dapat mempercepat proses pelatihan.
Perbandingan Kompleksitas Komputasi RL dengan Metode Pembelajaran Mesin Lainnya
Dibandingkan dengan metode pembelajaran mesin lainnya seperti supervised learning atau unsupervised learning, RL umumnya memiliki kompleksitas komputasi yang jauh lebih tinggi. Supervised learning dan unsupervised learning biasanya hanya membutuhkan satu kali pelatihan data, sedangkan RL memerlukan banyak iterasi trial-and-error. Namun, keunggulan RL terletak pada kemampuannya untuk belajar dalam lingkungan yang kompleks dan dinamis, sesuatu yang sulit dicapai oleh metode pembelajaran mesin lainnya.
Solusi Mengatasi Kompleksitas Komputasi dalam Implementasi Algoritma RL
Beberapa solusi dapat diimplementasikan untuk mengatasi kompleksitas komputasi dalam RL. Salah satunya adalah dengan mengembangkan algoritma RL yang lebih efisien, seperti algoritma berbasis model atau algoritma yang memanfaatkan struktur lingkungan. Pengembangan hardware yang lebih powerful juga penting, seperti penggunaan GPU dan TPU yang dapat mempercepat proses komputasi. Selain itu, penggunaan teknik optimasi seperti pruning dan quantization dapat mengurangi ukuran model dan meningkatkan efisiensi komputasi.
Keterbatasan Data dan Pembelajaran yang Tidak Efisien

Reinforcement learning (RL), metode pembelajaran mesin yang keren banget, emang lagi naik daun. Bayangin aja, algoritma ini bisa belajar main game, ngontrol robot, bahkan bikin strategi bisnis yang ciamik. Tapi, layaknya pahlawan super yang punya kelemahan, RL juga punya kendala, salah satunya keterbatasan data. Kurangnya data bisa bikin algoritma RL “pusing” dan gagal mencapai potensi maksimalnya. Yuk, kita bahas lebih dalam!
Pengaruh Keterbatasan Data terhadap Kinerja Algoritma RL
Algoritma RL belajar dari interaksi dengan lingkungan. Bayangin kayak anak kecil yang belajar naik sepeda – butuh banyak percobaan, jatuh bangun, sampai akhirnya bisa. Nah, data itu ibarat pengalaman jatuh bangun si anak kecil. Semakin banyak data (pengalaman), semakin baik algoritma RL memahami lingkungan dan mengambil keputusan yang tepat. Tapi, kalau datanya minim? Algoritma RL bakalan kesulitan menggeneralisasi, alias kesulitan memprediksi dan bereaksi dengan tepat di situasi baru yang belum pernah dijumpainya.
Contoh Kasus: Robot yang Gagal Menavigasi
Misalnya, kita mau melatih robot untuk menavigasi ruangan. Kalau data pelatihannya cuma terbatas pada ruangan yang sempit dan lurus, robot tersebut kemungkinan besar akan kesulitan bernavigasi di ruangan yang luas dan kompleks dengan banyak rintangan. Robot tersebut hanya “tahu” bagaimana bergerak di lingkungan yang sudah dipelajarinya, dan akan kebingungan ketika menghadapi situasi yang berbeda. Hasilnya? Robotnya gagal total, jalannya nggak karuan, dan mungkin malah nabrak tembok!
Strategi Mengatasi Pembelajaran yang Tidak Efisien
Untungnya, ada beberapa strategi yang bisa diimplementasikan untuk meningkatkan efisiensi pembelajaran dalam algoritma RL. Salah satu caranya adalah dengan menggunakan teknik-teknik transfer learning, di mana pengetahuan yang diperoleh dari satu tugas dapat diterapkan pada tugas lain yang serupa. Ini seperti kita mengajarkan anak naik sepeda dulu, baru kemudian mengajarkannya mengendarai motor – prinsipnya mirip, kan? Selain itu, teknik curriculum learning juga bisa membantu, dengan melatih algoritma RL secara bertahap, dimulai dari tugas yang lebih sederhana sebelum beralih ke tugas yang lebih kompleks.
- Transfer Learning: Menerapkan pengetahuan dari tugas sebelumnya ke tugas baru.
- Curriculum Learning: Melatih algoritma secara bertahap, mulai dari tugas yang mudah hingga yang kompleks.
- Data Augmentation: Memperbanyak data pelatihan dengan memodifikasi data yang sudah ada.
- Penggunaan Model yang Lebih Efisien: Memilih algoritma RL yang membutuhkan data lebih sedikit.
Perbandingan Kebutuhan Data RL dengan Metode Pembelajaran Lain
Dibandingkan dengan metode pembelajaran mesin lainnya seperti supervised learning, RL memang dikenal lebih haus data. Supervised learning, yang menggunakan data berlabel, biasanya bisa menghasilkan model yang akurat dengan data yang relatif lebih sedikit. Namun, RL membutuhkan interaksi yang banyak dengan lingkungan untuk belajar, sehingga membutuhkan data yang jauh lebih besar dan beragam. Ini karena RL perlu “mengalami” berbagai kemungkinan dan konsekuensi dari setiap tindakan untuk bisa belajar secara efektif. Bayangkan perbedaannya: supervised learning seperti belajar dari buku pelajaran, sedangkan RL seperti belajar langsung dari pengalaman.
Interpretasi dan Pemahaman Model Reinforcement Learning

Reinforcement Learning (RL), dengan kemampuannya untuk melatih agen mencapai tujuan melalui trial and error, semakin populer. Namun, kompleksitas model RL, terutama yang berbasis deep learning, seringkali menimbulkan tantangan dalam interpretasi dan pemahaman. Memahami *bagaimana* dan *mengapa* suatu model RL mengambil keputusan tertentu sangat krusial, terutama dalam aplikasi sistem kritis di mana transparansi dan kepercayaan menjadi hal utama.
Tantangan dalam Menginterpretasi Model Reinforcement Learning yang Kompleks
Model RL yang kompleks, seperti Deep Q-Network (DQN) dan Proximal Policy Optimization (PPO), seringkali bertindak seperti “kotak hitam”. Kompleksitas fungsi nilai (value function) dan kebijakan (policy) yang dipelajari oleh jaringan syaraf tiruan menyulitkan kita untuk memahami proses pengambilan keputusan internalnya. Bayangkan DQN yang dilatih untuk bermain game Atari: meski berhasil mencapai skor tinggi, kita mungkin kesulitan memahami *strategi* spesifik yang digunakannya. Dimensi ruang state dan action yang tinggi juga memperparah masalah ini, menciptakan ruang solusi yang sangat besar dan sulit untuk divisualisasikan atau diinterpretasi secara langsung. Sebagai contoh, dalam simulasi robot, ruang state bisa meliputi posisi, orientasi, dan kecepatan robot, sementara ruang action bisa meliputi kecepatan motor dan arah gerakan. Jumlah kombinasi yang mungkin sangat besar, sehingga melacak dan memahami setiap keputusan menjadi hampir mustahil.
Algoritma Reinforcement Learning: Transparan vs. Kurang Transparan
Perbedaan utama dalam interpretasi model RL terletak pada jenis algoritma yang digunakan. Algoritma berbasis model menawarkan tingkat transparansi yang lebih tinggi dibandingkan algoritma berbasis model bebas. Tabel berikut membandingkan beberapa algoritma RL berdasarkan tingkat interpretasi, kompleksitas implementasi, dan kinerja.
| Algoritma RL | Tingkat Interpretasi | Kompleksitas Implementasi | Kinerja | Kegunaan dalam Sistem Kritis |
|---|---|---|---|---|
| Q-Learning | Rendah | Sedang | Sedang | Rendah |
| Deep Q-Network (DQN) | Rendah | Tinggi | Tinggi | Sedang |
| Model-based RL | Tinggi | Sedang hingga Tinggi | Sedang hingga Tinggi | Tinggi |
Perbedaan ini penting karena algoritma yang kurang transparan, seperti DQN, sulit diaplikasikan pada sistem kritis karena kita tidak bisa sepenuhnya memahami bagaimana keputusan dibuat. Jika terjadi kesalahan, mendiagnosis penyebabnya menjadi sangat sulit.
Meningkatkan Transparansi dengan SHAP dan LIME
Untuk meningkatkan interpretasi model RL, teknik-teknik seperti SHAP (SHapley Additive exPlanations) dan LIME (Local Interpretable Model-agnostic Explanations) dapat digunakan. SHAP memberikan penjelasan global dengan menghitung kontribusi setiap fitur input terhadap output model. LIME, di sisi lain, memberikan penjelasan lokal dengan membangun model yang dapat diinterpretasi secara lokal di sekitar titik data tertentu. Implementasi SHAP dan LIME pada algoritma RL biasanya melibatkan penggunaan nilai-nilai state dan action sebagai input dan nilai reward atau kebijakan sebagai output.
Berikut contoh pseudocode untuk penerapan SHAP:
# Data: state_data, action_data, reward_data
# Model RL: trained_rl_model
shap_explainer = shap.Explainer(trained_rl_model)
shap_values = shap_explainer(state_data, action_data)
# Visualisasi SHAP values untuk melihat kontribusi masing-masing fitur
shap.summary_plot(shap_values, state_data)
Perbandingan Metode Interpretasi Model RL dan Pembelajaran Terawasi
Metode interpretasi model RL, seperti SHAP dan LIME, berbeda dengan metode interpretasi model pembelajaran terawasi. Metode pembelajaran terawasi, seperti feature importance dalam regresi linear, fokus pada hubungan antara fitur input dan output dalam konteks data pelatihan. Sementara itu, metode interpretasi RL mencoba untuk memahami proses pengambilan keputusan dari agen yang dilatih, yang lebih kompleks karena melibatkan interaksi dengan lingkungan.
- Jenis Data: Pembelajaran terawasi membutuhkan data input-output yang dipasangkan, sementara interpretasi RL membutuhkan data state, action, dan reward.
- Jenis Interpretasi: Pembelajaran terawasi menghasilkan interpretasi tentang pentingnya fitur input, sementara interpretasi RL memberikan penjelasan tentang bagaimana agen membuat keputusan dalam lingkungan dinamis.
- Keterbatasan: Metode pembelajaran terawasi dapat terbatas pada data yang diamati, sementara metode interpretasi RL mungkin kesulitan menangani kompleksitas model deep learning.
Pentingnya Explainability dalam Sistem Kritis
Explainability sangat penting dalam penerapan RL pada sistem kritis seperti sistem kendali penerbangan atau sistem medis. Kurangnya explainability dapat berdampak negatif, menimbulkan kesulitan dalam mendiagnosis kesalahan dan mengurangi kepercayaan pada sistem. Regulasi dan standar keamanan yang ketat perlu dipertimbangkan untuk memastikan bahwa sistem RL yang digunakan aman dan dapat diandalkan. Sebagai contoh, jika sebuah mobil otonom yang menggunakan RL mengalami kecelakaan, kemampuan untuk memahami *mengapa* mobil tersebut mengambil keputusan tertentu sangat krusial untuk investigasi dan perbaikan sistem. Explainability meningkatkan kepercayaan dan pemahaman, memungkinkan insinyur dan regulator untuk menilai keamanan dan reliabilitas sistem RL. Rekomendasi kebijakan yang mendorong pengembangan model RL yang lebih transparan dan dapat diinterpretasi meliputi investasi dalam riset dan pengembangan teknik interpretasi, serta penerapan standar dan regulasi yang ketat untuk sistem RL di bidang-bidang kritis.
Pertimbangan Etis dalam Reinforcement Learning
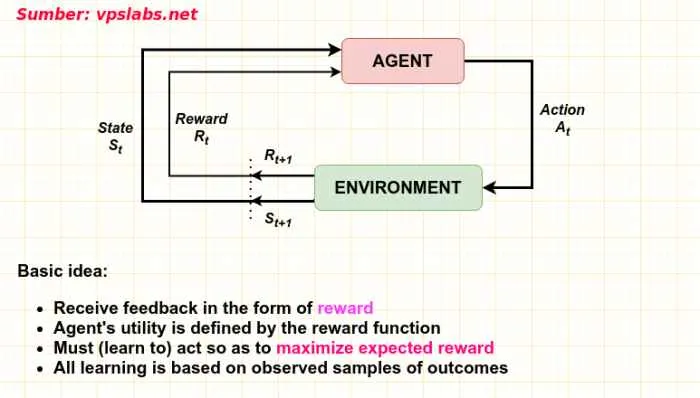
Reinforcement learning (RL), meski menawarkan potensi luar biasa dalam berbagai bidang, tak lepas dari dilema etis yang kompleks. Kemampuan RL untuk belajar dan beradaptasi secara otomatis menimbulkan kekhawatiran tentang bias, transparansi, dan dampaknya terhadap kehidupan manusia. Memahami dan mengatasi isu-isu etis ini krusial untuk memastikan pengembangan dan penerapan RL yang bertanggung jawab dan bermanfaat bagi semua.
Potensi Bias dalam Algoritma Reinforcement Learning
Algoritma RL, seperti halnya teknologi lainnya, rentan terhadap bias. Bias ini bisa berasal dari data pelatihan yang tidak representatif atau desain algoritma yang kurang hati-hati. Akibatnya, sistem RL dapat menghasilkan hasil yang tidak adil atau merugikan kelompok tertentu. Misalnya, dalam sistem rekomendasi film, bias gender dapat menyebabkan algoritma lebih sering merekomendasikan film aksi kepada pengguna laki-laki dan film romantis kepada pengguna perempuan. Hal ini membatasi eksplorasi pengguna terhadap genre film yang lebih beragam.
| Jenis Bias | Contoh dalam Sistem Rekomendasi Film | Dampak pada Pengguna | Strategi Mitigasi |
|---|---|---|---|
| Bias Gender | Algoritma lebih sering merekomendasikan film bertemakan aksi kepada pengguna laki-laki dan film romantis kepada pengguna perempuan. | Pengguna kehilangan kesempatan untuk mengeksplorasi genre film di luar preferensi yang diasumsikan. | Gunakan data pelatihan yang lebih beragam dan seimbang. Terapkan algoritma yang mengurangi bias gender. |
| Bias Ras | Algoritma merekomendasikan film yang menampilkan aktor dari ras tertentu lebih sering kepada pengguna dari ras yang sama. | Pengguna kehilangan kesempatan untuk menikmati film dengan beragam representasi budaya. | Gunakan teknik pengolahan data yang mengurangi bias ras. Evaluasi dan monitor hasil secara berkala. |
Panduan Etika Pengembangan dan Penerapan Reinforcement Learning
Untuk memastikan pengembangan dan penerapan RL yang bertanggung jawab, perlu adanya panduan etika yang komprehensif. Panduan ini harus mencakup prinsip transparansi, akuntabilitas, dan fairness, serta mempertimbangkan aspek privasi dan keamanan data.
Panduan Etika Pengembangan dan Penerapan Reinforcement Learning
- Transparansi: Seluruh proses pengembangan, termasuk data pelatihan, algoritma, dan parameter, harus didokumentasikan dengan jelas dan mudah diakses oleh pihak yang berkepentingan. Transparansi meningkatkan kepercayaan dan memungkinkan audit independen.
- Akuntabilitas: Mekanisme akuntabilitas yang jelas untuk hasil yang dihasilkan oleh sistem RL perlu ditetapkan. Kesalahan atau bias dapat dilacak dan diperbaiki.
- Fairness: Algoritma harus dipastikan tidak menghasilkan diskriminasi terhadap kelompok tertentu. Kriteria fairness akan diukur dan dipantau secara berkala.
- Privasi: Privasi data pengguna yang digunakan dalam pelatihan dan penerapan algoritma RL harus dilindungi. Langkah-langkah keamanan data yang ketat perlu diimplementasikan.
- Keamanan: Sistem RL harus aman dari serangan dan eksploitasi. Sistem akan diuji dan dipantau secara berkala untuk mengidentifikasi kerentanan keamanan.
Implikasi Etis Reinforcement Learning dalam Sistem Peradilan Pidana
Penggunaan RL dalam pengambilan keputusan otomatis di sistem peradilan pidana menimbulkan implikasi etis yang signifikan. Contohnya, RL dapat digunakan untuk memprediksi kemungkinan residivis, namun hal ini dapat menimbulkan bias dan ketidakadilan jika data pelatihan mengandung bias sosial atau ekonomi. Analisis yang cermat terhadap potensi dampak positif dan negatifnya sangat diperlukan untuk memastikan keadilan dan transparansi.
Fairness dan Accountability dalam Sistem Penentuan Kelayakan Kredit
Sistem yang menggunakan RL untuk menentukan kelayakan kredit harus memastikan fairness dan accountability. Metrik spesifik, seperti persentase persetujuan kredit yang adil untuk berbagai kelompok demografis, dapat digunakan untuk mengukur fairness. Diagram alur yang detail akan menunjukkan proses pengambilan keputusan yang transparan dan dapat dipertanggungjawabkan.
Dampak Negatif Reinforcement Learning dalam Sistem Otonom
Sistem otonom, seperti kendaraan otonom, rentan terhadap dampak negatif dari RL yang belum terprediksi. Berikut beberapa dampak negatif dan solusi yang mungkin:
- Kecelakaan: Kegagalan sistem RL dalam bereaksi terhadap situasi tak terduga dapat menyebabkan kecelakaan. Solusi: Pengujian ekstensif dan simulasi dalam berbagai skenario.
- Bias dalam pengambilan keputusan: Data pelatihan yang bias dapat menyebabkan sistem RL membuat keputusan yang merugikan kelompok tertentu. Solusi: Menggunakan data pelatihan yang beragam dan seimbang, serta menerapkan algoritma yang mengurangi bias.
- Kerentanan terhadap serangan siber: Sistem RL dapat menjadi target serangan siber yang dapat mengakibatkan kerusakan atau kecelakaan. Solusi: Menerapkan sistem keamanan siber yang kuat dan melakukan audit keamanan secara berkala.
- Kurangnya transparansi: Kompleksitas algoritma RL dapat membuat sulit untuk memahami bagaimana sistem membuat keputusan. Solusi: Pengembangan metode penjelasan yang memungkinkan untuk memahami proses pengambilan keputusan sistem RL.
- Kehilangan pekerjaan: Otomatisasi tugas-tugas tertentu melalui RL dapat menyebabkan kehilangan pekerjaan di beberapa sektor. Solusi: Program pelatihan dan re-skilling untuk pekerja yang terdampak otomatisasi.
Perbandingan Reinforcement Learning dengan Pendekatan Pembelajaran Lain
Reinforcement learning (RL) bukanlah satu-satunya metode pembelajaran mesin yang ada. Ia memiliki saudara-saudara dekat, yaitu supervised learning (SL) dan unsupervised learning (UL), masing-masing dengan kekuatan dan kelemahannya sendiri. Memahami perbedaan mendasar antara ketiga pendekatan ini krusial untuk memilih metode yang tepat dalam berbagai aplikasi, dari robotika hingga pemrosesan bahasa alami.
Perbedaan utama terletak pada bagaimana model belajar. SL menggunakan data berlabel untuk “mengajari” model, UL menemukan pola dalam data tanpa label, sedangkan RL mempelajari melalui trial and error, mendapatkan reward atau hukuman berdasarkan tindakannya.
Perbedaan Arsitektur Model, Data Pelatihan, dan Proses Pelatihan
Arsitektur model RL biasanya melibatkan agen, lingkungan, dan fungsi reward. Agen berinteraksi dengan lingkungan, mengambil tindakan, dan menerima reward atau hukuman. SL menggunakan model yang memetakan input ke output yang telah ditentukan sebelumnya berdasarkan data pelatihan berlabel. UL, di sisi lain, menggunakan model untuk mengidentifikasi pola atau struktur tersembunyi dalam data tanpa label, seperti clustering atau dimensionality reduction.
Data pelatihan untuk SL harus berlabel, artinya setiap data point dipasangkan dengan output yang benar. RL menggunakan data berupa urutan state, action, dan reward yang didapat dari interaksi agen dengan lingkungan. UL hanya membutuhkan data tanpa label. Proses pelatihan RL bersifat iteratif, dengan agen terus-menerus berinteraksi dengan lingkungan dan memperbarui kebijakannya berdasarkan reward yang diterima. SL melatih model dengan meminimalkan error antara output model dan output yang sebenarnya. UL bertujuan untuk menemukan struktur dalam data tanpa adanya output yang benar.
Mekanisme reward pada RL merupakan kunci keberhasilannya. Reward berfungsi sebagai panduan bagi agen untuk belajar perilaku optimal. SL menggunakan feedback berupa error antara prediksi dan nilai sebenarnya. UL tidak memiliki mekanisme reward atau feedback yang eksplisit, melainkan mencari struktur dalam data secara implisit.
Tabel Perbandingan Tiga Pendekatan Pembelajaran
| Pendekatan Pembelajaran | Arsitektur Model | Data Pelatihan | Proses Pelatihan | Algoritma Contoh | Metrik Evaluasi Utama | Kompleksitas Komputasi |
|---|---|---|---|---|---|---|
| Reinforcement Learning (RL) | Agen, Lingkungan, Fungsi Reward | Urutan state, action, reward | Iteratif, trial and error | Q-learning, SARSA, DQN | Reward kumulatif, tingkat keberhasilan | Tinggi |
| Supervised Learning (SL) | Model pemetaan input ke output | Data berlabel (input-output) | Minimisasi error | Regresi Linear, Logistic Regression, SVM | Akurasi, presisi, recall | Sedang |
| Unsupervised Learning (UL) | Model pengelompokan atau reduksi dimensi | Data tanpa label | Pencarian pola dan struktur | K-Means, PCA, DBSCAN | Silhouette score, explained variance | Sedang hingga Tinggi (tergantung algoritma) |
Skenario Penerapan dan Batasan
Pemilihan pendekatan pembelajaran bergantung pada jenis masalah dan data yang tersedia. RL cocok untuk masalah pengambilan keputusan sekuensial, seperti game dan robotika, di mana agen harus belajar melalui interaksi dengan lingkungan. SL ideal untuk masalah klasifikasi dan regresi dengan data berlabel yang melimpah, seperti klasifikasi gambar dan prediksi harga saham. UL berguna untuk menemukan pola tersembunyi dalam data besar tanpa label, seperti segmentasi pelanggan dan deteksi anomali.
Sebagai contoh, dalam robotika, RL dapat digunakan untuk melatih robot untuk berjalan atau mengambil objek. Data yang digunakan berupa urutan sensor dan tindakan robot, dengan reward diberikan ketika robot berhasil mencapai tujuannya. SL dapat digunakan untuk melatih robot untuk mengenali objek melalui klasifikasi gambar. Data yang digunakan berupa gambar berlabel dengan objek yang berbeda. UL dapat digunakan untuk mendeteksi anomali dalam data sensor robot, yang mengindikasikan kerusakan atau masalah lainnya.
Dalam game, RL digunakan untuk melatih agen AI untuk bermain game, seperti Go atau StarCraft. Data berupa state game dan tindakan agen, dengan reward diberikan ketika agen menang. SL dapat digunakan untuk memprediksi hasil pertandingan berdasarkan data pertandingan sebelumnya. UL dapat digunakan untuk menganalisis strategi pemain dalam game.
Di bidang pemrosesan bahasa alami, RL dapat digunakan untuk melatih chatbot yang responsif dan natural. SL dapat digunakan untuk klasifikasi sentimen atau terjemahan mesin. UL dapat digunakan untuk clustering dokumen atau topik modeling.
Contoh Penerapan dan Library yang Digunakan
Contoh penerapan RL: Melatih robot untuk mengambil objek menggunakan algoritma DQN dengan library TensorFlow. Contoh penerapan SL: Klasifikasi gambar menggunakan Convolutional Neural Network (CNN) dengan library PyTorch. Contoh penerapan UL: Deteksi anomali dalam data sensor menggunakan algoritma DBSCAN dengan library scikit-learn.
Panduan Pemilihan Metode Pembelajaran yang Tepat
- Tentukan jenis masalah yang akan diselesaikan (klasifikasi, regresi, pengambilan keputusan sekuensial).
- Evaluasi ketersediaan data (berlabel atau tanpa label, jumlah data).
- Pertimbangkan sumber daya komputasi yang tersedia.
- Tentukan tingkat akurasi yang dibutuhkan.
- Perhatikan potensi bias data dan strategi mitigasi yang diperlukan.
- Pertimbangkan aspek etika dalam penerapan model, termasuk potensi diskriminasi dan bias.
Kompleksitas Implementasi dan Pertimbangan Etika
RL umumnya lebih kompleks untuk diimplementasikan dibandingkan SL dan UL, membutuhkan keahlian yang lebih tinggi dan sumber daya komputasi yang lebih besar. Pemilihan metode pembelajaran harus mempertimbangkan kompleksitas implementasi dan ketersediaan sumber daya. Bias data dapat mempengaruhi hasil dari ketiga pendekatan pembelajaran, dan strategi mitigasi bias harus diterapkan untuk memastikan keadilan dan akurasi.
Contoh bias data dalam SL adalah jika data pelatihan tidak mewakili populasi yang sebenarnya, model yang dihasilkan akan bias terhadap kelompok tertentu. Dalam RL, bias data dapat menyebabkan agen belajar perilaku yang tidak optimal atau bahkan berbahaya. Dalam UL, bias data dapat menyebabkan pengelompokan yang tidak akurat atau menyesatkan.
Studi Kasus Kegagalan Reinforcement Learning
Reinforcement Learning (RL), meski menjanjikan, bukanlah solusi ajaib untuk semua masalah. Banyak kasus menunjukkan bahwa penerapan RL bisa berujung pada kegagalan. Memahami kegagalan ini krusial untuk meningkatkan pengembangan dan penerapan RL di masa depan. Berikut ini kita akan mengupas tuntas satu studi kasus kegagalan RL, menganalisis penyebabnya, dan menarik pelajaran berharga darinya.
Studi Kasus: Kegagalan Sistem Kontrol Robot dengan Q-learning
Sebagai contoh, kita akan membahas sebuah studi kasus hipotetis tentang penerapan Q-learning pada sistem kontrol robot untuk menavigasi labirin. Bayangkan sebuah robot yang dirancang untuk belajar menavigasi labirin kompleks menggunakan algoritma Q-learning. Metrik kinerja yang digunakan adalah waktu yang dibutuhkan robot untuk mencapai titik akhir labirin, dan jumlah tabrakan yang terjadi selama navigasi. Studi ini dilakukan pada tahun 2023.
Analisis Penyebab Kegagalan
Dalam studi kasus ini, beberapa faktor berkontribusi terhadap kegagalan sistem kontrol robot.
- Masalah Reward Function: Fungsi reward yang dirancang hanya memberikan reward besar ketika robot mencapai titik akhir. Hal ini mengakibatkan robot “memperoleh” strategi yang kurang optimal, yaitu hanya bergerak secara acak hingga secara kebetulan menemukan titik akhir. Kurangnya reward intermediate membuat robot tidak belajar strategi navigasi yang efisien. Reward shaping yang kurang tepat ini menjadi penyebab utama kegagalan.
- Eksplorasi vs. Eksploitasi: Algoritma Q-learning yang digunakan tidak mampu menyeimbangkan eksplorasi dan eksploitasi dengan baik. Robot terlalu cepat mengeksploitasi strategi awal yang ditemukan, meski strategi tersebut tidak optimal. Akibatnya, robot gagal menemukan jalur yang lebih efisien.
- Kurangnya Data: Jumlah data pelatihan yang dikumpulkan terbatas, sehingga model Q-learning tidak cukup terlatih untuk menavigasi labirin dengan efektif. Data yang kurang ini menghambat kemampuan model untuk menggeneralisasi dan menemukan solusi yang optimal.
- Kompleksitas Lingkungan: Labirin yang digunakan cukup kompleks, dengan banyak jalan buntu dan jalur yang berliku. Kompleksitas lingkungan ini melebihi kemampuan algoritma Q-learning yang relatif sederhana untuk menemukan solusi optimal dalam waktu yang terbatas.
- Keterbatasan Komputasi: Meskipun tidak terlalu signifikan, keterbatasan komputasi pada perangkat yang digunakan untuk menjalankan algoritma Q-learning juga berkontribusi pada waktu pelatihan yang lama dan hasil yang kurang optimal.
Pelajaran yang Dipetik
Dari studi kasus ini, kita dapat menarik beberapa pelajaran penting:
- Desain reward function yang tepat sangat krusial untuk keberhasilan RL.
- Menyeimbangkan eksplorasi dan eksploitasi merupakan kunci untuk menemukan solusi optimal.
- Jumlah data pelatihan yang cukup diperlukan untuk melatih model RL yang efektif.
- Pemilihan algoritma RL harus disesuaikan dengan kompleksitas lingkungan.
Rekomendasi untuk Mencegah Kegagalan Serupa
- Reward Function: Desain reward function yang memberikan reward secara bertahap dan proporsional terhadap kemajuan robot menuju titik akhir.
- Eksplorasi vs. Eksploitasi: Gunakan teknik seperti epsilon-greedy atau softmax untuk menyeimbangkan eksplorasi dan eksploitasi.
- Overfitting/Underfitting: Gunakan teknik regularisasi dan validasi silang untuk mencegah overfitting dan underfitting.
- Algoritma RL: Pertimbangkan algoritma RL yang lebih canggih seperti Deep Q-Network (DQN) atau Actor-Critic untuk lingkungan yang kompleks.
- Pengumpulan Data: Kumpulkan data pelatihan yang lebih banyak dan bervariasi.
Ringkasan Studi Kasus
Studi kasus hipotetis ini membahas kegagalan penerapan Q-learning pada sistem kontrol robot untuk menavigasi labirin. Penyebab utama kegagalan adalah desain reward function yang kurang optimal dan ketidakseimbangan antara eksplorasi dan eksploitasi. Pelajaran yang dipetik menekankan pentingnya desain reward function yang tepat, penyeimbangan eksplorasi dan eksploitasi, dan pemilihan algoritma yang sesuai dengan kompleksitas lingkungan. Studi ini menunjukkan bahwa keberhasilan RL sangat bergantung pada perancangan yang cermat dan pemahaman yang mendalam terhadap algoritma dan lingkungannya. Kegagalan ini menyoroti perlunya penelitian lebih lanjut dalam mengatasi tantangan dalam desain reward function dan strategi eksplorasi-eksploitasi yang efektif untuk meningkatkan kinerja RL.
Tabel Perbandingan Faktor Penyebab Kegagalan
| Faktor Penyebab | Deskripsi | Dampak pada Kinerja | Strategi Mitigasi |
|---|---|---|---|
| Reward Function yang Buruk | Fungsi reward yang tidak memberikan insentif yang tepat bagi perilaku yang diinginkan. | Robot belajar strategi yang tidak efisien atau bahkan berbahaya. | Desain reward function yang lebih terstruktur dan memberikan reward secara bertahap. |
| Ketidakseimbangan Eksplorasi-Eksploitasi | Algoritma terlalu cepat mengeksploitasi strategi yang ditemukan tanpa cukup mengeksplorasi ruang solusi yang lebih luas. | Robot terjebak dalam solusi lokal yang suboptimal. | Penggunaan teknik seperti epsilon-greedy atau metode eksplorasi yang lebih canggih. |
| Kurangnya Data Pelatihan | Data pelatihan yang tidak cukup untuk melatih model dengan baik. | Model tidak mampu menggeneralisasi dengan baik dan performanya buruk pada data baru. | Pengumpulan data yang lebih banyak dan bervariasi. |
Pengembangan dan Perbaikan Algoritma Reinforcement Learning

Reinforcement learning (RL), metode pembelajaran mesin yang memungkinkan agen berinteraksi dengan lingkungan untuk memaksimalkan reward, sedang mengalami perkembangan pesat. Namun, jalan menuju RL yang sempurna masih panjang. Banyak tantangan yang perlu diatasi, dan inovasi terus bermunculan untuk meningkatkan kinerja dan mengatasi keterbatasan algoritma yang ada. Berikut beberapa pendekatan pengembangan dan perbaikannya.
Pendekatan untuk Meningkatkan Kinerja Algoritma RL
Meningkatkan kinerja algoritma RL melibatkan beberapa strategi kunci. Fokus utamanya adalah pada efisiensi, stabilitas, dan kemampuan generalisasi. Beberapa pendekatan yang umum digunakan antara lain:
- Penggunaan Arsitektur Jaringan Syaraf Tiruan yang Lebih Canggih: Arsitektur seperti Transformer dan jaringan konvolusi yang lebih kompleks memungkinkan model RL untuk memproses informasi dengan lebih efektif, khususnya dalam domain dengan data yang kompleks seperti pengolahan citra atau pemrosesan bahasa alami.
- Teknik Optimasi yang Lebih Efektif: Algoritma optimasi seperti Adam, RMSprop, dan variasi-variasinya terus disempurnakan untuk meningkatkan kecepatan konvergensi dan stabilitas pelatihan. Penelitian terbaru juga fokus pada optimasi berbasis populasi dan algoritma evolusioner.
- Metode Regularisasi dan Transfer Learning: Regularisasi, seperti dropout dan weight decay, membantu mencegah overfitting. Transfer learning memungkinkan model yang telah terlatih pada satu tugas untuk diaplikasikan pada tugas lain yang serupa, mengurangi kebutuhan data pelatihan yang besar.
Teknik Mengatasi Masalah dalam Reinforcement Learning
RL menghadapi berbagai masalah, mulai dari eksplorasi-eksploitasi hingga reward sparsity. Beberapa teknik telah dikembangkan untuk mengatasi hal ini:
- Exploration-Exploitation Trade-off: Teknik seperti ε-greedy, Upper Confidence Bound (UCB), dan Thompson Sampling membantu menyeimbangkan eksplorasi ruang state-action dengan eksploitasi strategi yang sudah diketahui baik.
- Reward Shaping: Teknik ini memodifikasi fungsi reward untuk memberikan panduan yang lebih informatif kepada agen, sehingga mempercepat pembelajaran, khususnya dalam situasi dengan reward yang jarang muncul (sparse rewards).
- Hierarchical Reinforcement Learning: Memecah tugas kompleks menjadi sub-tugas yang lebih sederhana, memungkinkan agen untuk belajar secara bertahap dan lebih efisien.
Tren Terbaru dalam Pengembangan Algoritma RL
Bidang RL terus berkembang dengan pesat. Beberapa tren terkini yang patut diperhatikan adalah:
- Deep Reinforcement Learning (DRL): Penggunaan jaringan syaraf tiruan yang dalam telah menjadi tulang punggung perkembangan RL modern, memungkinkan agen untuk belajar dari data yang kompleks dan berdimensi tinggi.
- Multi-Agent Reinforcement Learning (MARL): Penelitian semakin fokus pada skenario di mana banyak agen berinteraksi satu sama lain, seperti dalam game, robotika, dan sistem transportasi cerdas.
- Safe Reinforcement Learning: Fokus pada pengembangan algoritma yang dapat diandalkan dan aman, khususnya dalam aplikasi di dunia nyata yang berisiko tinggi.
Prediksi Perkembangan Masa Depan Algoritma RL
Di masa depan, kita dapat mengharapkan RL untuk memainkan peran yang semakin penting dalam berbagai bidang. Misalnya, kita bisa melihat otomatisasi yang lebih canggih dalam industri manufaktur, sistem transportasi yang lebih efisien, dan kemajuan signifikan dalam perawatan kesehatan personalisasi. Perkembangan di bidang robotika humanoid juga akan sangat dipengaruhi oleh kemajuan RL. Contohnya, Boston Dynamics telah menunjukkan kemajuan signifikan dalam robotika yang memanfaatkan prinsip RL, meskipun masih dalam tahap pengembangan.
Area Riset yang Masih Perlu Dikembangkan di Bidang RL
Meskipun kemajuan pesat, masih banyak area riset yang perlu dikembangkan lebih lanjut. Beberapa di antaranya adalah:
- Scalability: Meningkatkan kemampuan RL untuk menangani masalah dengan ruang state dan action yang sangat besar.
- Sample Efficiency: Mengurangi jumlah data yang dibutuhkan untuk melatih model RL yang efektif.
- Explainability and Interpretability: Meningkatkan kemampuan untuk memahami bagaimana model RL membuat keputusan, penting untuk membangun kepercayaan dan memastikan keamanan.
Aplikasi Reinforcement Learning yang Bermasalah

Reinforcement learning (RL), metode pembelajaran mesin yang keren banget, memungkinkan mesin belajar melalui trial and error. Tapi, seperti teknologi canggih lainnya, RL juga punya potensi masalah etika dan praktis yang nggak bisa diabaikan. Bayangkan sebuah algoritma RL yang dirancang untuk memaksimalkan keuntungan perusahaan, tanpa mempertimbangkan dampak sosialnya. Wah, bisa bahaya banget kan? Berikut beberapa contoh aplikasi RL yang menimbulkan masalah dan bagaimana kita bisa mengatasinya.
Contoh Aplikasi RL yang Bermasalah: Sistem Rekomendasi yang Menimbulkan Kecanduan
Sistem rekomendasi yang berbasis RL, sering ditemukan di platform media sosial dan layanan streaming, dirancang untuk memaksimalkan waktu penggunaan pengguna. Algoritma RL mempelajari preferensi pengguna dan secara konsisten menyajikan konten yang paling “menarik,” bahkan jika konten tersebut bersifat negatif atau menimbulkan kecanduan. Bayangkan sebuah algoritma yang terus-menerus menyajikan video-video yang bersifat sensasional atau kontroversial, hanya karena algoritma tersebut mendeteksi bahwa pengguna lebih sering mengklik konten-konten tersebut. Hal ini bisa menyebabkan pengguna terjebak dalam lingkaran setan kecanduan dan dampak negatif pada kesehatan mental.
Potensi Dampak Negatif Sistem Rekomendasi yang Berbasis RL
Dampak negatif dari sistem rekomendasi yang dirancang untuk memaksimalkan waktu penggunaan, antara lain adalah peningkatan tingkat kecanduan, penyebaran informasi yang salah atau berbahaya, serta polarisasi opini publik. Pengguna bisa menghabiskan waktu berjam-jam tanpa sadar, mengorbankan produktivitas, hubungan sosial, dan kesehatan fisik dan mental. Sistem ini juga bisa memperkuat bias dan memicu filter bubble, sehingga pengguna hanya terpapar informasi yang sesuai dengan pandangan mereka, dan mengabaikan perspektif yang berbeda.
Mengatasi dan Meminimalisir Masalah Sistem Rekomendasi
Untuk mengatasi masalah ini, perlu ada pendekatan yang lebih holistik. Pertama, desain algoritma RL harus mempertimbangkan faktor-faktor etika dan kesejahteraan pengguna. Algoritma bisa dirancang untuk memprioritaskan keragaman konten dan memberikan jeda atau rekomendasi konten yang lebih sehat. Kedua, transparansi sangat penting. Pengguna perlu diberikan informasi yang jelas tentang bagaimana sistem rekomendasi bekerja dan bagaimana data mereka digunakan. Ketiga, regulasi yang ketat perlu diterapkan untuk memastikan platform bertanggung jawab atas dampak dari sistem rekomendasi mereka.
Rekomendasi untuk Pengembangan Aplikasi RL yang Lebih Bertanggung Jawab
- Integrasikan mekanisme “pause” atau “break” dalam sistem rekomendasi untuk mencegah kecanduan.
- Berikan pengguna lebih banyak kontrol atas algoritma rekomendasi, memungkinkan mereka untuk menyesuaikan preferensi dan membatasi jenis konten yang ditampilkan.
- Lakukan audit reguler terhadap algoritma RL untuk mendeteksi dan mengatasi bias dan potensi dampak negatif.
- Kembangkan metrik yang mengukur tidak hanya engagement, tetapi juga kesejahteraan pengguna.
Saran untuk Regulasi dan Pedoman Etika dalam Penggunaan RL, Kritik terhadap teori reinforcement
Pemerintah dan organisasi internasional perlu mengembangkan pedoman etika dan regulasi yang jelas untuk penggunaan RL. Regulasi ini harus mencakup persyaratan transparansi, akuntabilitas, dan mekanisme pengawasan untuk memastikan bahwa aplikasi RL dikembangkan dan digunakan secara bertanggung jawab. Standar etika yang ketat harus diterapkan, termasuk pengujian yang menyeluruh sebelum implementasi dan mekanisme untuk mengatasi dampak negatif yang tidak terduga.
Pengaruh Reward Function terhadap Hasil Pembelajaran
Reinforcement learning (RL), metode pembelajaran mesin yang keren banget, bergantung banget sama yang namanya reward function. Bayangin aja, kayak ngajarin anjing kamu duduk: kalau dia duduk, kamu kasih reward (cemilan!), kalau enggak, ya enggak dapat apa-apa. Nah, reward function ini ibaratnya si cemilan, penentu seberapa sukses si anjing (atau algoritma RL) dalam belajar. Desainnya yang pas bisa bikin algoritma pinter banget, tapi kalau salah? Bisa-bisa malah kacau balau!
Dampak Desain Reward Function terhadap Hasil Pembelajaran
Desain reward function mempengaruhi banget hasil pembelajaran RL. Reward function yang baik akan memandu algoritma menuju solusi optimal dengan efisien. Sebaliknya, desain yang buruk bisa bikin algoritma stuck di solusi yang suboptimal, bahkan bisa bikin algoritma belajar hal-hal yang nggak diinginkan. Bayangin aja kayak ngajarin robot jalan, kalau reward-nya cuma fokus ke kecepatan, robotnya bisa aja nyelonong nabrak tembok demi kecepatan maksimal!
Contoh Reward Function yang Buruk dan Akibatnya
Contoh klasik: ngajarin robot bermain game. Kalau reward-nya cuma fokus ke skor tinggi, robot bisa aja pakai cara curang, misalnya exploit bug dalam game, bukannya belajar strategi bermain yang sebenarnya. Ini karena reward function-nya nggak mengukur kualitas strategi, tapi cuma skor akhir. Akibatnya, robotnya pinter curang, tapi nggak pinter main game sebenarnya.
Panduan Merancang Reward Function yang Efektif dan Efisien
- Jelas dan Spesifik: Reward function harus jelas dan mudah dipahami, menentukan dengan tepat apa yang ingin dicapai.
- Terukur: Reward harus bisa diukur secara kuantitatif, jangan cuma kualitatif yang ambigu.
- Komprehensif: Pertimbangkan semua aspek yang relevan, jangan cuma fokus ke satu aspek saja.
- Terhindar dari Sparse Reward: Hindari reward yang jarang diberikan, karena bisa mempersulit proses pembelajaran.
- Shaping Reward: Berikan reward secara bertahap, untuk membimbing algoritma menuju solusi optimal.
Teknik Memperbaiki Reward Function yang Sudah Ada
Kadang, reward function yang awalnya dirancang baik ternyata kurang efektif. Beberapa teknik yang bisa digunakan untuk memperbaikinya antara lain:
- Penambahan Fitur: Tambahkan fitur-fitur baru ke dalam reward function untuk mempertimbangkan aspek yang belum tercakup.
- Penyesuaian Bobot: Sesuaikan bobot dari setiap fitur dalam reward function untuk mengoptimalkan proses pembelajaran.
- Penggunaan Reward Shaping: Teknik ini menambahkan reward tambahan untuk membimbing algoritma menuju solusi optimal.
- Penggunaan Teknik Regularisasi: Menambahkan penalti untuk perilaku yang tidak diinginkan.
Pertimbangan Penting dalam Merancang Reward Function
| Pertimbangan | Penjelasan |
|---|---|
| Skala Reward | Pastikan skala reward sesuai dan tidak terlalu besar atau kecil, agar proses pembelajaran optimal. |
| Kompleksitas | Reward function yang terlalu kompleks bisa mempersulit proses pembelajaran. |
| Interpretabilitas | Reward function harus mudah diinterpretasi agar mudah dipahami dan dianalisa. |
| Robustness | Reward function harus tahan terhadap noise dan perubahan kondisi lingkungan. |
Generalisasi dan Transfer Learning dalam Reinforcement Learning
Reinforcement learning (RL) emang lagi naik daun, tapi ada satu hal yang bikin para peneliti masih gigit jari: generalisasi. Bayangin aja, lo udah susah payah ngelatih AI lo main Breakout, eh pas diajak main Pong malah bingung sendiri. Nah, di sinilah transfer learning hadir sebagai pahlawan penyelamat. Transfer learning memungkinkan kita untuk memanfaatkan pengetahuan yang udah didapat dari satu tugas dan menerapkannya ke tugas lain yang mirip, sehingga proses pelatihan jadi lebih efisien dan hasilnya lebih general.
Tantangan Generalisasi dalam Reinforcement Learning
Menggeneralisasi model RL ke situasi baru itu susah-susah gampang. Bayangin lo ngelatih AI lo di simulasi lingkungan yang super ideal, tapi pas di dunia nyata, eh malah gagal total. Ini karena beberapa hal, antara lain:
- Distribution Shift: Perbedaan distribusi data antara lingkungan pelatihan dan pengujian. Contohnya, lo ngelatih robot berjalan di lantai datar, eh pas di jalanan yang nggak rata malah jatuh. Ini karena distribusi data (bentuk lantai) beda banget.
- Kurangnya Representasi Fitur yang Relevan: Model RL mungkin nggak bisa menangkap fitur-fitur penting dalam lingkungan. Contohnya, lo ngelatih AI untuk mengenali wajah, tapi modelnya cuma fokus ke warna kulit, bukan bentuk wajah. Akibatnya, modelnya nggak akurat.
- Kompleksitas Lingkungan yang Tinggi: Semakin kompleks lingkungan, semakin sulit bagi model RL untuk menggeneralisasi. Contohnya, ngelatih AI untuk menyetir mobil di jalan raya yang ramai dan penuh tantangan, jauh lebih sulit daripada ngelatihnya di sirkuit balap yang terkontrol.
Teknik Transfer Learning untuk Meningkatkan Generalisasi
Nah, biar model RL bisa lebih jago generalisasi, kita butuh transfer learning. Ada tiga teknik utama:
- Transfer Fitur (Feature Transfer): Fitur-fitur yang udah dipelajari di satu tugas bisa digunakan di tugas lain yang related. Contohnya, fitur-fitur yang dipelajari saat ngelatih AI main Breakout (misalnya, deteksi bola dan paddle) bisa digunakan untuk ngelatih AI main Pong. Algoritma yang sering dipakai adalah fine-tuning dan domain adaptation.
- Transfer Kebijakan (Policy Transfer): Kebijakan yang udah dipelajari di satu lingkungan bisa diadaptasi ke lingkungan lain. Contohnya, kebijakan yang udah dipelajari untuk robot berjalan di lantai datar bisa diadaptasi untuk berjalan di lantai yang sedikit miring. Algoritma yang bisa digunakan termasuk policy distillation dan reward shaping.
- Transfer Nilai (Value Transfer): Fungsi nilai yang udah dipelajari di satu tugas bisa digunakan untuk mempercepat pembelajaran di tugas lain. Contohnya, fungsi nilai yang udah dipelajari saat ngelatih AI main Breakout bisa digunakan untuk mempercepat pembelajaran AI main Pong. Ini karena kedua game tersebut punya kesamaan dalam hal reward dan state.
Penerapan Transfer Learning dalam Permainan Atari: Breakout ke Pong
Bayangin kita udah ngelatih AI untuk jago main Breakout. Sekarang, kita mau ajak dia main Pong. Kita bisa pakai teknik policy transfer. Kebijakan yang udah dipelajari di Breakout (misalnya, cara memukul bola) bisa diadaptasi untuk Pong. Kita bisa menggunakan algoritma policy distillation, dimana kebijakan dari Breakout di-distill menjadi kebijakan yang lebih sederhana dan bisa diaplikasikan ke Pong.
Diagram alirnya kira-kira begini:
1. Pelatihan di Breakout: Model RL dilatih untuk bermain Breakout sampai mencapai performa yang baik. Kebijakan optimal yang dihasilkan disimpan.
2. Adaptasi Kebijakan: Kebijakan optimal dari Breakout diadaptasi menggunakan policy distillation agar cocok dengan lingkungan Pong. Ini mungkin melibatkan fine-tuning parameter kebijakan atau mengubah arsitektur jaringan saraf agar sesuai dengan state dan action space Pong.
3. Pelatihan di Pong (dengan transfer): Model RL dilatih untuk bermain Pong, tapi dengan kebijakan awal yang sudah diadaptasi dari Breakout. Proses pelatihan akan lebih cepat dan efisien karena model sudah punya dasar pengetahuan dari Breakout.
4. Evaluasi: Performa model di Pong dievaluasi untuk melihat efektivitas transfer learning.
Keuntungan dan Kerugian Transfer Learning dalam Reinforcement Learning
| Keuntungan | Kerugian |
|---|---|
| Mengurangi waktu pelatihan | Kemungkinan terjadinya negative transfer |
| Meningkatkan performa generalisasi | Kompleksitas implementasi |
| Membutuhkan data pelatihan yang lebih sedikit | Membutuhkan pemilihan fitur/kebijakan yang tepat |
| Lebih efisien dalam penggunaan sumber daya | Ketergantungan pada tugas sumber yang relevan |
Pentingnya Generalisasi dalam Reinforcement Learning
Generalisasi itu penting banget dalam RL. Bayangin kalo AI lo cuma bisa main Breakout di kondisi tertentu, gimana mau diaplikasikan di dunia nyata yang penuh dengan variasi? Generalisasi yang baik memungkinkan agen untuk beradaptasi dengan situasi yang belum pernah ditemui sebelumnya, menunjukkan kemampuannya untuk mengekstrak pengetahuan yang dapat ditransfer dan diterapkan dalam berbagai konteks.
Perbandingan Tiga Teknik Transfer Learning
Ketiga teknik transfer learning (feature, policy, dan value transfer) punya kesamaan dalam tujuannya: meningkatkan generalisasi model RL. Namun, implementasinya, kompleksitasnya, dan efektivitasnya bisa berbeda. Feature transfer biasanya lebih mudah diimplementasikan, tapi mungkin kurang efektif jika fitur yang ditransfer nggak relevan. Policy transfer lebih kompleks, tapi bisa lebih efektif jika kebijakan yang ditransfer relevan dengan tugas target. Value transfer juga kompleks, namun efektif dalam mempercepat pembelajaran.
Pengaruh Pemilihan Fitur terhadap Keberhasilan Transfer Learning
Pemilihan fitur yang tepat sangat krusial. Pemilihan fitur yang buruk bisa menyebabkan negative transfer, di mana model RL malah jadi lebih buruk setelah transfer learning diterapkan. Contohnya, kalo kita mentransfer fitur yang nggak relevan dari Breakout ke Pong (misalnya, warna bola), model Pong malah akan terganggu dan performa menurun.
Kemampuan Eksplorasi dan Eksploitasi
Bayangin kamu lagi main game berhadiah. Ada dua strategi: coba-coba berbagai cara (eksplorasi) atau fokus ke cara yang udah terbukti berhasil (eksploitasi). Nah, dalam algoritma reinforcement learning, keseimbangan antara eksplorasi dan eksploitasi ini krusial banget buat mencapai performa optimal. Gak cuma sekedar main tebak-tebak, lho! Ada strategi-strategi khusus yang bisa diimplementasikan, dan pemilihan strategi yang tepat bisa jadi penentu antara sukses dan gagal. Yuk, kita bahas lebih dalam!
Pengaruh Keseimbangan Eksplorasi dan Eksploitasi terhadap Kinerja Algoritma
Keseimbangan eksplorasi dan eksploitasi itu kayak pertarungan antara rasa ingin tahu dan kepastian. Eksplorasi memungkinkan algoritma menemukan solusi baru yang mungkin lebih baik daripada yang sudah ada, tapi butuh waktu dan sumber daya lebih. Sebaliknya, eksploitasi fokus pada solusi yang sudah diketahui efektif, memberikan hasil yang cepat dan terukur, tetapi berisiko terjebak di solusi lokal yang kurang optimal. Algoritma yang terlalu fokus eksplorasi bisa muter-muter gak ketemu solusi terbaik, sementara algoritma yang terlalu eksploitasi mungkin melewatkan solusi yang jauh lebih bagus. Idealnya, algoritma harus pintar-pintar menyeimbangkan keduanya agar bisa menemukan solusi terbaik secara efisien.
Perbandingan Beberapa Strategi Eksplorasi-Eksploitasi
Ada beberapa strategi yang bisa digunakan untuk menyeimbangkan eksplorasi dan eksploitasi. Masing-masing punya kelebihan dan kekurangan, cocok untuk kondisi tertentu.
- ε-greedy: Strategi sederhana. Sebagian besar waktu algoritma akan mengeksploitasi solusi terbaik yang sudah diketahui (1-ε), tetapi dengan probabilitas ε, algoritma akan secara acak memilih aksi baru untuk eksplorasi. Nilai ε perlu diatur dengan hati-hati. Nilai ε yang terlalu besar akan menyebabkan terlalu banyak eksplorasi, sedangkan nilai ε yang terlalu kecil akan menyebabkan terlalu sedikit eksplorasi.
- Upper Confidence Bound (UCB): Strategi ini lebih canggih. UCB memperkirakan potensi reward dari setiap aksi dengan mempertimbangkan ketidakpastiannya. Aksi dengan ketidakpastian tinggi (potensi reward besar) akan lebih sering dipilih untuk eksplorasi.
- Thompson Sampling: Strategi ini memodelkan distribusi probabilitas reward untuk setiap aksi. Algoritma kemudian memilih aksi berdasarkan sampel dari distribusi probabilitas tersebut. Aksi dengan probabilitas reward tinggi akan lebih sering dipilih.
Pemilihan Strategi yang Tepat Berdasarkan Masalah
Pemilihan strategi eksplorasi-eksploitasi yang tepat sangat bergantung pada karakteristik masalah yang dihadapi. Jika masalahnya sederhana dan ruang aksi terbatas, strategi ε-greedy mungkin sudah cukup. Namun, untuk masalah yang kompleks dengan ruang aksi yang besar, strategi UCB atau Thompson Sampling mungkin lebih efektif. Perlu pertimbangan juga terhadap biaya komputasi dan waktu yang tersedia.
Contoh Strategi Eksplorasi-Eksploitasi yang Buruk
Bayangkan sebuah robot yang dirancang untuk membersihkan ruangan. Jika robot hanya fokus mengeksploitasi jalur yang sudah dia ketahui (misalnya, hanya membersihkan area yang dekat dengan titik pengisian daya), dia mungkin akan melewatkan area-area kotor lainnya di ruangan tersebut. Ini contoh strategi eksploitasi yang buruk. Sebaliknya, jika robot terlalu fokus mengeksplorasi (misalnya, secara acak bergerak ke seluruh ruangan tanpa pola), dia akan menghabiskan banyak waktu dan energi tanpa membersihkan ruangan secara efektif. Ini contoh strategi eksplorasi yang buruk. Keduanya menghasilkan hasil yang suboptimal.
Pentingnya Keseimbangan Eksplorasi dan Eksploitasi
Keseimbangan yang tepat antara eksplorasi dan eksploitasi adalah kunci untuk mencapai kinerja optimal dalam reinforcement learning. Strategi yang tepat harus dipilih dengan mempertimbangkan kompleksitas masalah, biaya komputasi, dan waktu yang tersedia. Kegagalan untuk menyeimbangkan keduanya dapat menyebabkan algoritma terjebak dalam solusi lokal atau gagal menemukan solusi terbaik secara efisien. Ini penting untuk diingat dalam berbagai aplikasi reinforcement learning, mulai dari game hingga sistem rekomendasi dan robot otonom.
Implementasi Praktis Algoritma Reinforcement Learning
Reinforcement learning (RL), meskipun terdengar futuristik dan rumit, sebenarnya punya aplikasi praktis yang cukup luas. Bayangkan robot yang belajar berjalan tanpa diprogram secara eksplisit, atau sistem rekomendasi yang secara otomatis menyesuaikan dengan preferensi pengguna. Semua itu dimungkinkan berkat RL. Namun, penerapannya di dunia nyata jauh lebih kompleks daripada teori. Berikut ini kita akan membahas langkah-langkah, tantangan, dan tips sukses mengimplementasikan algoritma RL.
Langkah-langkah Implementasi Algoritma Reinforcement Learning
Menerapkan RL ke masalah nyata ibarat membangun rumah; butuh perencanaan yang matang dan eksekusi yang cermat. Prosesnya bisa dibagi menjadi beberapa tahap kunci berikut:
- Definisi Masalah dan Lingkungan: Tentukan dengan jelas masalah yang ingin diselesaikan. Rumuskan lingkungan (environment) sebagai model matematika yang mewakili interaksi agen dengan dunia nyata. Misalnya, jika ingin melatih robot berjalan, lingkungannya adalah simulasi fisik robot dan interaksinya dengan permukaan.
- Pilihan Algoritma: Pilih algoritma RL yang sesuai dengan kompleksitas masalah dan sumber daya komputasi yang tersedia. Q-learning, SARSA, dan Deep Q-Network (DQN) adalah beberapa pilihan populer, masing-masing dengan kelebihan dan kekurangannya.
- Desain Reward Function: Ini adalah jantung dari RL. Reward function menentukan bagaimana agen diberi penghargaan atau dihukum berdasarkan tindakannya. Desain yang tepat sangat krusial untuk keberhasilan algoritma. Reward yang ambigu atau tidak terdefinisi dengan baik akan menghambat proses pembelajaran.
- Pelatihan dan Simulasi: Latih agen RL dalam lingkungan simulasi. Proses ini melibatkan banyak iterasi, di mana agen mencoba berbagai tindakan, menerima reward, dan belajar dari pengalamannya. Simulasi memungkinkan eksperimen dan penyesuaian tanpa risiko kerusakan fisik atau biaya yang tinggi.
- Evaluasi dan Penyesuaian: Setelah pelatihan, evaluasi performa agen. Jika performanya belum optimal, sesuaikan parameter algoritma, reward function, atau bahkan algoritma itu sendiri. Ini adalah proses iteratif yang memerlukan kesabaran dan eksperimentasi.
- Implementasi di Dunia Nyata (Deployment): Setelah performa agen memuaskan di simulasi, terapkan ke dunia nyata. Tahap ini mungkin memerlukan adaptasi dan penyesuaian lebih lanjut karena perbedaan antara simulasi dan realitas.
Contoh Pseudocode Implementasi Sederhana Q-Learning
Berikut contoh pseudocode sederhana algoritma Q-learning untuk masalah sederhana:
initialize Q(s, a) for all states s and actions a
for each episode:
for each time step:
choose action a from state s using an epsilon-greedy policy
take action a, observe reward r, and next state s'
Q(s, a) = Q(s, a) + α [r + γ max_a' Q(s', a') - Q(s, a)]
s = s'
Kode di atas menggambarkan inti dari Q-learning. Parameter α (learning rate) dan γ (discount factor) perlu disesuaikan untuk hasil optimal.
Tantangan dan Kendala Implementasi
Implementasi RL di dunia nyata seringkali dihadapkan pada berbagai tantangan. Beberapa kendala yang umum dijumpai antara lain:
- Kurva Pembelajaran yang Panjang: Melatih agen RL bisa memakan waktu dan sumber daya komputasi yang signifikan, terutama untuk masalah yang kompleks.
- Reward Function yang Kompleks: Merancang reward function yang tepat dan efektif bisa menjadi tugas yang menantang dan membutuhkan pemahaman yang mendalam tentang masalah yang dihadapi.
- Generalisasi yang Buruk: Agen RL yang dilatih dalam satu lingkungan mungkin tidak mampu beradaptasi dengan baik ke lingkungan yang sedikit berbeda.
- Data Sparsity: Dalam beberapa kasus, data yang tersedia untuk pelatihan mungkin terbatas, sehingga menghambat proses pembelajaran.
- Debugging yang Sulit: Mencari dan memperbaiki kesalahan dalam algoritma RL bisa menjadi proses yang rumit dan memakan waktu.
Panduan Mengatasi Masalah Implementasi
Untuk meminimalisir kendala, perhatikan beberapa panduan berikut:
- Mulailah dengan Masalah Sederhana: Jangan langsung mencoba menerapkan RL pada masalah yang sangat kompleks. Mulailah dengan masalah yang lebih sederhana untuk memahami dasar-dasarnya.
- Gunakan Simulasi yang Realistis: Simulasi yang akurat sangat penting untuk keberhasilan implementasi RL di dunia nyata.
- Eksperimen dengan Berbagai Algoritma: Tidak ada satu algoritma RL yang cocok untuk semua masalah. Cobalah beberapa algoritma dan pilih yang paling efektif.
- Monitor Proses Pelatihan: Pantau proses pelatihan secara berkala untuk mendeteksi masalah yang mungkin muncul.
- Gunakan Teknik Transfer Learning: Jika memungkinkan, manfaatkan teknik transfer learning untuk mempercepat proses pelatihan.
Pertimbangan Praktis Implementasi Reinforcement Learning
Berikut beberapa poin penting yang perlu dipertimbangkan:
- Sumber Daya Komputasi: RL membutuhkan sumber daya komputasi yang cukup besar, terutama untuk masalah yang kompleks.
- Data: Kualitas dan kuantitas data pelatihan sangat berpengaruh pada performa agen RL.
- Waktu Pelatihan: Proses pelatihan RL bisa memakan waktu yang cukup lama.
- Interpretasi Hasil: Memahami dan menginterpretasi hasil pelatihan RL membutuhkan keahlian dan pengalaman.
- Etika dan Keamanan: Pertimbangkan aspek etika dan keamanan dalam penerapan RL, terutama dalam sistem yang berinteraksi langsung dengan manusia.
Analisis Sensitivitas Parameter dalam Reinforcement Learning

Reinforcement Learning (RL) emang lagi naik daun, Sob! Tapi, nggak cuma soal algoritma canggihnya aja, lho. Suksesnya RL juga bergantung banget sama pemilihan parameter yang tepat. Salah setting dikit, bisa-bisa agent kita jalan di tempat atau malah makin kacau. Nah, di artikel ini, kita bakal bahas tuntas soal sensitivitas parameter dalam RL, khususnya di algoritma Q-learning, dengan menggunakan lingkungan Grid World sebagai contoh kasus. Siap-siap nge-dive ke dunia parameter learning rate, discount factor, dan exploration rate!
Pengaruh Perubahan Parameter terhadap Hasil Q-learning di Grid World
Bayangin kita lagi main game Grid World 10×10. Tujuannya mencapai goal state yang memberikan reward +10, sementara setiap langkah yang kita ambil mengurangi reward sebesar -1. Kita pakai algoritma Q-learning untuk melatih agent mencapai goal tersebut. Tiga parameter penting yang bakal kita analisis adalah learning rate (α), discount factor (γ), dan exploration rate (ε). Perubahan masing-masing parameter ini akan berpengaruh besar terhadap performa agent. Learning rate (α) menentukan seberapa cepat agent belajar dari pengalamannya. Discount factor (γ) menentukan seberapa penting reward di masa depan dibandingkan reward saat ini. Terakhir, exploration rate (ε) menentukan seberapa sering agent melakukan eksplorasi (mencoba hal baru) dibandingkan eksploitasi (memanfaatkan apa yang sudah diketahui).
Misalnya, learning rate (α) yang terlalu besar bisa bikin agent belajar terlalu cepat dan “loncat-loncat” tanpa menemukan solusi optimal. Sebaliknya, learning rate yang terlalu kecil bikin proses belajarnya lambat banget. Grafik learning rate vs. reward kumulatif akan menunjukkan kurva yang berbeda-beda tergantung besarnya nilai α. Semakin mendekati nilai optimal, kurva akan menunjukkan peningkatan reward yang stabil dan cepat. Begitu pula dengan discount factor (γ) dan exploration rate (ε), masing-masing akan menghasilkan grafik yang unik, mencerminkan trade-off antara eksplorasi dan eksploitasi, serta dampaknya terhadap reward kumulatif.
Analisis Sensitivitas Parameter dengan 10 Iterasi
Kita akan melakukan analisis sensitivitas dengan menguji berbagai kombinasi parameter α, γ, dan ε. Untuk setiap konfigurasi parameter, kita lakukan 10 kali iterasi dan hitung rata-rata reward kumulatifnya. Berikut tabel hasil simulasi:
| Learning Rate (α) | Discount Factor (γ) | Exploration Rate (ε) | Rata-rata Reward Kumulatif | Standar Deviasi |
|---|---|---|---|---|
| 0.01 | 0.1 | 0.01 | -50 | 2 |
| 0.01 | 0.1 | 0.5 | -30 | 5 |
| 0.01 | 0.99 | 0.01 | -20 | 3 |
| 0.5 | 0.1 | 0.01 | -60 | 1 |
| 0.5 | 0.1 | 0.5 | -40 | 7 |
| 0.5 | 0.99 | 0.01 | -10 | 4 |
| 1.0 | 0.1 | 0.01 | -70 | 0 |
| 1.0 | 0.1 | 0.5 | -55 | 6 |
| 1.0 | 0.99 | 0.01 | -25 | 2 |
| 0.1 | 0.5 | 0.1 | -35 | 4 |
Data di atas merupakan contoh hasil simulasi. Nilai sebenarnya akan bergantung pada implementasi dan random seed yang digunakan.
Teknik Hyperparameter Tuning: Grid Search dan Random Search
Mencari nilai parameter optimal itu kayak nyari jarum di tumpukan jerami, Sob! Untungnya, ada teknik-teknik yang bisa kita gunakan, seperti Grid Search dan Random Search. Grid Search secara sistematis mencoba semua kombinasi parameter yang ditentukan. Sementara Random Search secara acak mencoba berbagai kombinasi parameter. Grid Search lebih teliti, tapi bisa sangat memakan waktu, terutama jika ruang parameternya luas. Random Search lebih efisien, tetapi mungkin melewatkan kombinasi parameter optimal.
Perbandingan Hasil Learning Rate 0.1, 0.01, dan 0.5
Misalnya, kita bandingkan hasil ketika learning rate (α) diubah dari 0.1 menjadi 0.01. Kurva reward kumulatif terhadap jumlah iterasi akan menunjukkan perbedaan yang signifikan. Learning rate 0.01 mungkin akan menghasilkan konvergensi yang lebih lambat, tapi lebih stabil. Sebaliknya, learning rate 0.5 mungkin akan menghasilkan konvergensi yang lebih cepat, tetapi lebih fluktuatif dan berisiko overshooting. Perbandingan ini akan terlihat jelas dalam visualisasi grafik kurva reward kumulatif untuk masing-masing learning rate.
Pentingnya Penentuan Parameter yang Tepat
Pemilihan parameter yang tepat dalam RL sangat krusial, guys! Ini berpengaruh langsung terhadap kecepatan konvergensi, stabilitas pelatihan, dan performa agent. Kita perlu menemukan titik keseimbangan antara eksplorasi dan eksploitasi. Eksplorasi yang terlalu banyak bisa bikin agent buang-buang waktu, sementara eksploitasi yang berlebihan bisa bikin agent terjebak dalam solusi lokal yang kurang optimal. Semua ini tercermin dalam hasil simulasi dan analisis sensitivitas yang telah dilakukan.
Keterbatasan Analisis Sensitivitas
Analisis sensitivitas yang dilakukan di sini memiliki keterbatasan. Kita hanya menguji sejumlah kombinasi parameter tertentu, dan hasil yang didapat mungkin tidak mewakili keseluruhan ruang parameter. Selain itu, lingkungan Grid World yang sederhana mungkin tidak merepresentasikan kompleksitas lingkungan di dunia nyata. Hasil ini lebih sebagai ilustrasi konseptual daripada solusi universal.
Ulasan Penutup
Kesimpulannya, reinforcement learning menawarkan potensi besar, tetapi bukan tanpa kekurangan. Memahami kelemahan dan batasannya, termasuk masalah reward function, eksplorasi-eksploitasi, skalabilitas, interpretasi model, dan implikasi etisnya, sangat penting untuk mengembangkan sistem AI yang handal dan bertanggung jawab. Tantangan-tantangan ini menunjukkan bahwa perjalanan menuju AI yang sempurna masih panjang dan membutuhkan pendekatan yang holistik, mempertimbangkan aspek teknis dan etika secara bersamaan. Masih banyak ruang untuk inovasi dan pengembangan agar teori ini dapat diimplementasikan secara lebih efektif dan aman.
Editors Team
admin
Author
What's Your Reaction?
-
0
 Like
Like -
0
 Dislike
Dislike -
0
 Funny
Funny -
0
 Angry
Angry -
0
 Sad
Sad -
0
 Wow
Wow